
本文将和大家分享一些从互联网上爬取语料的经验。
0x1 工具准备
工欲善其事必先利其器,爬取语料的根基便是基于。
我们进行开发时,主要运用了几个关键模块,包括、lxml、json。
简单介绍一个各模块的功能
01|
它是一份外部工具,用来操作网址资源非常便捷。该项目的官方说明中印着响亮的标语:致力于让HTTP更易用。与系统自带的相比,个人感觉其操作感受强了很多倍。
我们简单的比较一下:
:
import urllib2 import urllib URL获取方式为特定链接,该链接指向豆瓣网,路径为v2/event/list,用于获取活动信息 #构建请求参数 参数使用urllib.urlencode方法进行编码,其中包含地点信息为108288,日期类型为周末,活动类型为展览,编码后的字符串依次为loc=108288,day_type=weekend,type=exhibition #发送请求 response = urllib2.urlopen一个连接请求,该请求的地址由URL_GET和params组合而成,组合方式为在URL_GET后加上一个问号,然后拼接params的字符串形式 #Response Headers print(response.info()) #Response Code print(response.getcode()) #Response Body print(response.read())
:
import requests URL_GET = "https://api.douban.com/v2/event/list" #构建请求参数 参数集合里,地点编号是108288,时间类别属于周末,活动性质为展览性质。 #发送请求 response是使用请求方法获取到的数据,URL_GET是目标网址,params是传递的参数信息 #Response Headers print(response.headers) #Response Code print(response.status_code) #Response Body print(response.text)
我们可以发现,这两种库还是有一些区别的:
参数的建立方式有两种,一种是必须对参数进行转换,这个过程比较复杂,另一种是不需要再进行转换,这个方法非常简单。
需要另外设计url参数的格式,使其满足特定规范;相比之下,直接获取预设链接和参数会简便许多。
连接方式,需要查看返回信息中的头部字段,当字段值为"close"时,代表每次请求完成后都会关闭通道,而库的使用方式则不同,它允许多次请求复用一个通道,字段值显示为"keep-alive",这种方式能节省更多资源
4. 编码方式:库的编码方式-更全,在此不做举例
综上所诉,使用更为简明、易懂,极大的方便我们开发。
02|lxml
它是一个集合,而XPath是一种方法,其中最常用的XPath集合是lxml。
获取返回页面中的目标信息时,如何有效提取所需数据呢?此时可借助功能卓越的lxml解析器处理HTML/XML文档。虽然市面上存在多种解析库,但为何优先选用lxml呢?为作比较,另选一款广受认可的HTML解析库进行对照分析。
我们简单的比较一下:
:
导入一个名为BeautifulSoup的模块,这个模块属于bs4这个包,在程序中使用时需要先加载进来
# 假设html是需要被解析的html
将HTML内容传递给BeautifulSoup的构造函数,可以获取一个代表文档的对象
这个代码片段创建了一个名为soup的对象,它使用BeautifulSoup库解析html字符串,解析器指定为html.parser,并且明确从编码utf-8中读取数据
#查找所有的h4标签
links = soup.find_all("h4")
lxml:
from lxml import etree
# 假设html是需要被解析的html
#将html传入etree 的构造方法,得到一个文档的对象
root = etree.HTML(html)
#查找所有的h4标签
links = root.xpath("//h4")
我们可以发现,这两种库还是有一些区别的:
解析HTML时,其处理方法与的编写风格相近,提供的接口设计十分便捷,能够运用css路径进行元素定位;而lxml的规则体系,需要花费一定时间来掌握
性能方面,基于DOM的处理方式需要加载全部文档,并对整个DOM树进行解析,这导致时间和内存消耗显著增加;相比之下,lxml仅进行局部遍历,并且是用C语言编写的,而非其他语言,因此在效率上明显优于lxml。
总而言之,选用更方便、更顺手,lxml虽然需要一定时间掌握,不过大体上也很清晰明了,关键在于它用C语言开发,运行效率极高,对于我这种有洁癖的人来说,不假思索就选择了lxml。
03|json
自带了处理json的模块,基础操作用它完全没问题。如果想更省事,也可以选用外部的json工具,比较流行的有这些。
这两种库,在模块运行效率方面表现更佳,编码与解码的效能也更为出色,并且其兼容性处理得更为周全。因此,若需选用方库,不妨加以采用。
0x2 确定语料源
将武器准备好之后,接下来就需要确定爬取方向。
电竞领域相关资料可作为参考,当前需采集此类信息。知名电竞站点包括企鹅电竞、企鹅电竞以及企鹅电竞(斜眼),因此选取企鹅电竞平台直播的游戏作为信息来源进行数据抓取。
我们访问了企鹅电竞的官方网站,切换到了游戏目录部分,页面上展示了许多游戏,手动录入这些游戏名称效率非常低,所以我们着手实施了爬虫计划的第一阶段,也就是游戏目录的自动获取。

import requests
from lxml import etree
# 更新游戏列表
def _updateGameList():
# 发送HTTP请求时的HEAD信息,用于伪装为浏览器
heads = {
'Connection': 'Keep-Alive',
'接受': '文本/HTML, 应用/XHTML+XML, 所有'
语言选项:英语美国优先,法语次要,中文简体中国大陆次之,中文简体一般情况再次之。
'内容编码': 'gzip', '内容压缩': 'deflate',
浏览器标识为:Mozilla版本六点一,运行在Windows NT六点三操作系统上,采用WOW64架构,使用Trident七点零内核,内部版本号为十一点零,整体表现类似Gecko引擎
}
# 需要爬取的游戏列表页
网址为https://egame.qq.com/gamelist, 这是一个游戏列表的链接,包含了众多游戏的详细信息,用户可以通过这个地址浏览和选择自己喜欢的游戏进行体验。
# 不压缩html,最大链接时间为10妙
请求通过指定网址获取数据,设置请求头信息,关闭证书验证功能,并设定超时时间为十秒,然后将响应结果赋值给变量res
# 为防止出错,编码utf-8
res.encoding = 'utf-8'
# 将html构建为Xpath模式
res的内容转换成HTML格式,然后赋值给root变量
# 使用Xpath语法,获取游戏名
游戏列表通过根节点下的XPath获取,路径为ul标签中class属性值为livelist-mod的元素,再从其子li标签中的p标签提取文本内容
# 输出爬到的游戏名
print(gameList)
我们手头拥有这几十个游戏名称之后,接下来需要针对这几十款游戏开展语料采集工作,此刻便产生了疑问,究竟应该从哪个平台去采集这几十款游戏的指南内容呢,是选择多玩网,还是17173网站?经过对这几个平台的研究,了解到这些平台仅包含部分热门游戏的文字资料,至于那些不太出名或者关注度不高的游戏,比如《灵魂筹码》、《奇迹:觉醒》、《死神来了》等,在这些平台上很难搜集到丰富的相关文献,具体情况请参考下图。
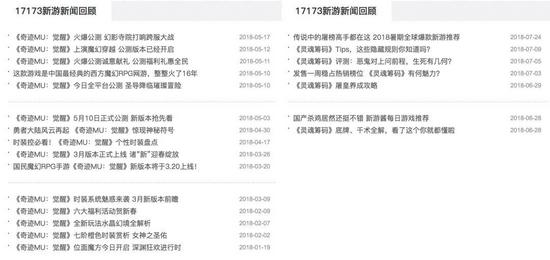
能够注意到,“ 奇迹:觉醒”、“灵魂筹码”的相关资料非常有限,数量上达不到我们的标准。 是否存在一个较为普遍的站点,它拥有极为充裕的资料内容,能够满足我们的需要。
实际上仔细琢磨一下,我们每天都会运用到的一个资源平台就是百度,通过在百度新闻进行游戏相关搜索,获取到的搜索结果清单,其条目指向的网页信息几乎都和搜索词高度契合,因此我们数据来源不足的困境便顺利化解了,不过随之而来的是另一个棘手难题,一个相当难办的事情,那就是怎样获取任意页面中的文章资料。
各个网站各自的页面布局互不相同,我们无从得知接下来会采集哪个网站的信息,而且为每个网站单独开发一套爬虫程序,其工作量实在庞大到超乎想象!然而,我们也不能不加区分地抓取页面中所有文字内容,若用这些材料来训练模型,过程必定异常艰难!
历经与众多平台反复较量,查阅大量信息并深入思考,最终获得一个相对通用的办法,现在向各位阐述我的思考过程。
0x3 任意网站的文章语料爬取
01|提取方法
1)基于Dom树正文提取
2)基于网页分割找正文块
3)基于标记窗的正文提取
4)基于数据挖掘或机器学习
5)基于行块分布函数正文提取
02|提取原理
大家看到这些种类时,是不是都感到不太明白,它们究竟是怎么取得的呢?请允许我逐步说明。
1)基于Dom树的正文提取:
这种技术核心在于先依据标准化的HTML构造文档对象模型,接着逐层扫描该模型,识别并区分广告条、导航链接以及其他次要元素,将上述非核心内容剥离出去,剩下的部分便构成了文章主体内容。
但是这种方法有两个问题
这种方法在处理遵循良好结构的HTML时效果显著,然而,一旦遇到未依照W3C标准编写的网页,其适用性便大打折扣。
建立树结构的过程以及对其进行遍历所需的时间成本和空间成本都相当可观,而且,遍历树的方法会根据具体的HTML元素类型而有所不同。
2) 基于网页分割找正文块 :
这种技术借助HTML中的分隔符,同时参考部分视觉元素,例如字体的色彩、尺寸和内容。
这种方法存在一个问题:
各个网站页面的构造差异很大,分隔方式难以一致,所以无法确保它们能够互相兼容。
3) 基于标记窗的正文提取:
介绍一个术语,称为标记窗,将两个标签及其包含的文本整合为一个标记窗,例如在“我是h1”中,“我是h1”即为标记窗内容,提取标记窗的文本。
这种技术首先提取文档的题目以及网页内容里的各类标签部分,接着对这些部分实施切分处理。随后测量标题的字符顺序与标签内容字符顺序的词汇间隔值L,倘若L低于某个界限值,便判定该标签区域包含的信息属于主体文本。
这种方法虽然看上去挺好,但其实也是存在问题的:
① 需要对页面中的所有文本进行分词,效率不高。
② 词语距离的阈值难以确定,不同的文章拥有不同的阈值。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取主文本。
这种办法确实非常出色,不过它要求事先准备好网页文档和文本资料,接着才能开展训练工作,这一点我们在此不作详细讨论。
5)基于行块分布函数正文提取
任何网页中,其内容与标记总是相互掺杂的,正文部分的特点在于:文字集中度高,段落长度适中,通常文字分布最为密集的区域就是正文部分,有时该部分可能占据最大篇幅,比如评论内容较多而正文较少,因此需要结合段落长度进行综合分析。
实现思路:
我们先对HTML进行脱标,仅保留全部内容文本,并记下标签移除后所有空隙的位置,这个文本版本称为Ctext。
② 对每一个Ctext取周围k行(k
③ 对去掉所有空白符,其文字总长度称为Clen;
以Ctext作为水平方向的标准,以各行Clen为垂直方向的标准,构建一个平面图示。
以这个网页为例,它的主要文本部分位于第145行和第182行之间。
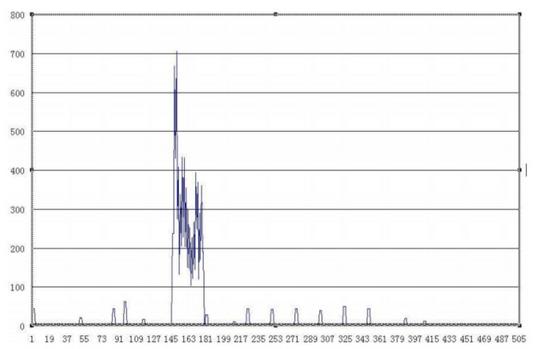
根据图片信息,准确的文本部分是分布函数图中存在极值且连续的那片地方,那里通常有一个突然上升的位置和一个突然下降的位置。所以,网页内容识别的难题变成了寻找行块分布曲线上的两个关键位置,分别是急剧上升点和急剧下降点。这两个关键位置所涵盖的范围,既包含了当前网页行块长度的最大值,又是连续的。
反复试验表明,该技术对中文网页主体内容的识别精确度很高,其长处在于,文本行检测机制不依赖HTML文档,和HTML标记没有关联,构建方便,效果精准。
主要逻辑代码如下:
# 假设content为已经拿到的html
# Ctext取周围k行(k<5),定为3
blocksWidth = 3
# 每一个Cblock的长度
Ctext_len = []
# Ctext
lines = content.split('n')
# 去空格
for i in range(len(lines)):
if lines[i] == ' ' or lines[i] == 'n':
lines[i] = ''
# 计算纵坐标,每一个Ctext的长度
for i in range(0, len(lines) - blocksWidth):
wordsNum = 0
for j in range(i, i + blocksWidth):
lines[j] = lines[j].replace("\s", "")
wordsNum += len(lines[j])
Ctext_len.append(wordsNum)
# 开始标识
start = -1
# 结束标识
end = -1
# 是否开始标识
boolstart = False
# 是否结束标识
boolend = False
# 行块的长度阈值
max_text_len = 88
# 文章主内容
main_text = []
# 没有分割出Ctext
if len(Ctext_len) < 3:
return '没有正文'
for i in range(len(Ctext_len) - 3):
# 如果高于这个阈值
if(Ctext_len[i] >max_text_len, 如果不是 boolstart 的真值
# Cblock下面3个都不为0,认为是正文
当Ctext_len[i + 1]的值不为零,或者Ctext_len[i + 2]的值不为零,亦或Ctext_len[i + 3]的值不为零的情况下
boolstart = True
start = i
continue
if (boolstart):
# Cblock下面3个中有0,则结束
当Ctext_len第i个值为零,或者Ctext_len第i加一个值为零时
end = i
boolend = True
tmp = []
# 判断下面还有没有正文
if(boolend):
ii从开始数到结束数,每个数都进行一次处理
if(len(lines[ii]) < 5):
continue
tmp.append(lines[ii] + "n")
str = "".join(list(tmp))
# 去掉版权信息
if ("Copyright" in str or "版权所有" in str):
continue
main_text.append(str)
boolstart = boolend = False
# 返回主内容
result = "".join(list(main_text))
0x4 结语
现在我们能够得到任何题材的文章资料了,不过这还只是第一步,收集到这些资料之后,我们还要再次进行整理、拆分、标记词性等操作,才能得到真正能够应用的资料。
总结
这里提供的是编辑向大家说明的任意HTML主体部分获取方法,目的是为了让大家受益匪浅,假如各位存在任何困惑,欢迎在下方发表留言,编辑将尽快作出回应,同时对于各位对脚本之家平台给予的关爱,表示由衷的感激。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 