
这是一个常用的数据分析库。它看起来很频繁,并且具有许多令人震惊的功能。即使是退伍军人也无法保证他们可以有效地将其用于数据分析。
本文的目的是为您提供一些有效且实用的技巧。
1。从剪贴板创建
本文中的()方法非常神奇。它可以将剪贴板中的数据转换为格式,这意味着可以直接将其复制在Excel中,并且可以快速转换为。
以以下Excel数据表为例,选择所有数据表,然后按Ctrl+C复制:
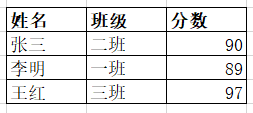
然后执行pd。()以获取相同的数据表:
pd.read_clipboard()
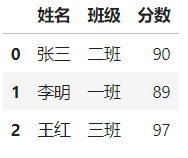
此功能是为分析师提供的福音,他们经常在Excel和Excel中切换。 Excel中的数据可以一键转换为可读格式。
2。选择数据类型
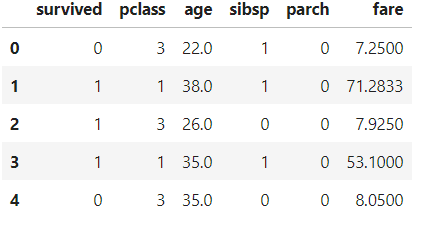
数据分析过程可能需要过滤数据列,例如数字列,以经典的泰坦尼克号数据集为例:
import seaborn as sns
# 导出泰坦尼克数据集
df = sns.load_dataset('titanic')
df.head()
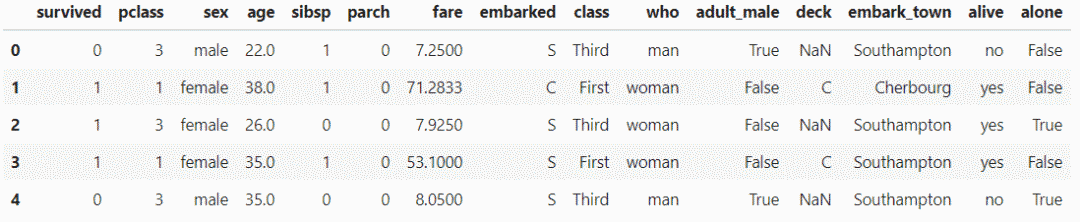
查看此数据集的每一列的数据类型:
df.dtypes
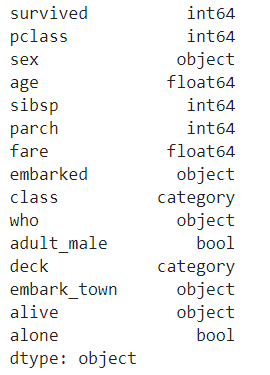
您可以看到每列的数据类型都不同,包括int,float,bool等。
如果我只需要一个数字列,即带有数据类型int和float的列,我可以通过该方法实现它:
df.select_dtypes(include='number').head()
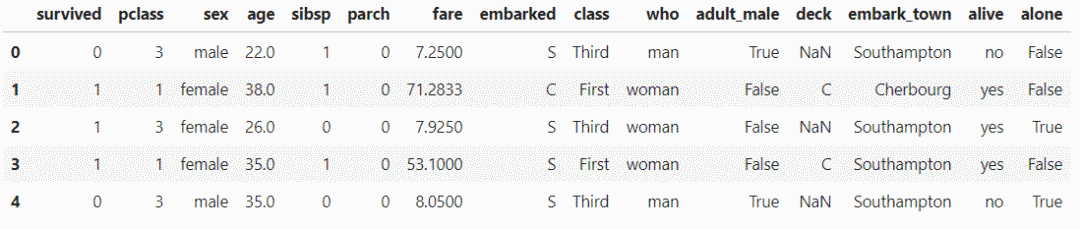
选择除数据类型INT以外的列,请注意,此处的参数是:
df.select_dtypes(exclude='int').head()
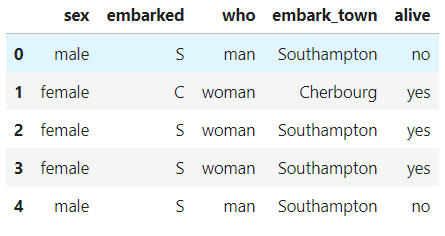
也可以选择多种数据类型:
df.select_dtypes(include=['int', 'datetime', 'object']).head()
3。更改为
在这种情况下,有两种将字符串更改为数字值的方法:
首先创建样本,看看两种方法的不同。
import pandas as pd
df = pd.DataFrame({ 'product': ['A','B','C','D'],
'price': ['10','20','30','40'],
'sales': ['20','-','60','-']
})
df
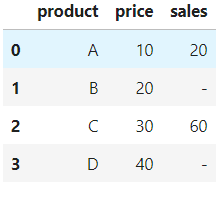
列是字符串类型。尽管价格和销售列的内容具有数字,但它们的数据类型也是字符串。
值得注意的是,价格列是所有数字,并且销售列有数字,但是空值被 - 取代。
df.dtypes

接下来,我们使用()方法将价格列的数据类型更改为int:
df['price'] = df['price'].astype(int)
# 或者用另一种方式
df = df.astype({'price': 'int'})
但是,如果您使用()方法更改销售列,则会获得错误:
df['sales'] = df['sales'].astype(int)
原因是在销售列中,还有 - 除了数字外,它是一个字符串,不能转换为int。
但是,()方法可以解决此问题,只需要设置参数=''。
df['sales'] = pd.to_numeric(df['sales'], errors='coerce')
df
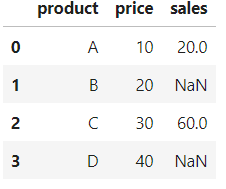
现在 - 在销售列中已被NAN替换,其数据类型也已成为浮动。
df.dtypes
4。检测和处理缺失值
有一种更通用的检测缺失值的方法是Info(),它可以计算每列未失弹值的数量。
或使用泰坦尼克号数据集:
import seaborn as sns
# 导出泰坦尼克数据集
df = sns.load_dataset('titanic')
df.info()
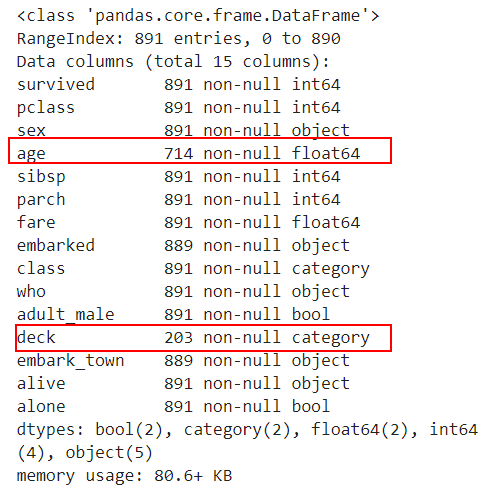
红色标记是具有缺失值的列,并给出了不可允许的值的数量。您可以计算列中有多少丢失值。
这可能不够直观,因此您可以使用df。()。sum()方法清楚地获取每列中有多少丢失值:
df.isnull().sum()

df。()。sum()。sum()可以返回此数据集中缺少值的总数:
df.isnull().sum().sum()
您还可以在此列中看到缺少值的比例,并使用df.isna()。均值()方法:
df.isna().mean()
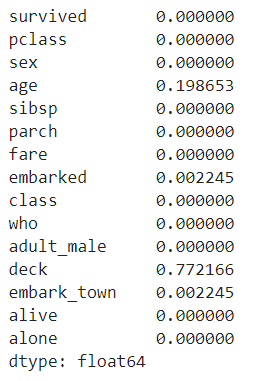
注意:使用()和isna()的效果相同。
那么如何处理丢失的值?
两种方式:删除和替换。
df.dropna(axis = 0)
df.dropna(axis = 1)
df.dropna(thresh=len(df)*0.9, axis=1)
df.fillna(value=10)
df.fillna(axis=0, method='ffill')
df.fillna(axis=1, method='ffill')
df.fillna(axis=0, method='bfill')
df.fillna(axis=1, method='bfill')
df['Age'].fillna(value=df['Age'].mean(), inplace=True)
当然,您还可以用最大和最小值,分位数等替换缺失值。
5。离散的连续数据
在数据准备过程中,通常将现有功能组合或转换以创建一个新功能,其中连续数据的离散化是一种非常重要的功能转换方法,即将数值变为类别特征。
以泰坦尼克号数据集为例,其中有一列显示年龄特征:
import seaborn as sns
# 导出泰坦尼克数据集
df = sns.load_dataset('titanic')
df['age'].head()

如果我们想将年龄分组为一个分类特征,例如(例如
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 