
这篇文章的内容源自华为云社区,标题为《【华为云MySQL技术专栏】(for MySQL)与MySQL的COUNT查询并行优化策略-云社区-华为云》,作者是数据库。
1.背景介绍
计数表格中的行数是用户程序和数据库管理员维护时经常执行的任务。尽管MySQL作为主流的在线事务处理数据库被广泛采用,不过针对庞大表格实施计数操作会耗费大量时间,缘由在于:
计数操作必须扫描数据表的全部记录才能得到准确的记录数量,如果数据量很大或者部分数据不在内存池中,检索过程会非常缓慢。
MySQL 8.0.14的早期版本不包含并行查询功能,因此只能按顺序处理SQL语句,无法借助多核心硬件提升运算效率。
MySQL 8.0.14及以后版本允许并行地检索主键数据,却不允许并行地查询二级索引信息,当主键数据量非常庞大而二级索引数据量相对较少的情况下,与MySQL 5.7旧版本相比,社区版并行检索二级索引时可能会出现效率降低的问题,并且无法禁用并行检索主键的功能。
针对MySQL,运用自主研发的并行查询功能以及计算下放技术,成功应对了海量数据表计数效率低下的难题,在常见应用模式下,其处理速度比传统MySQL主键并行扫描方式快上八十倍以上。
2. MySQL COUNT并行介绍
该版本存储引擎能够并行检查主键,借助并行处理的优势来提升计数操作的运行速度,具体功能展示在图1中。
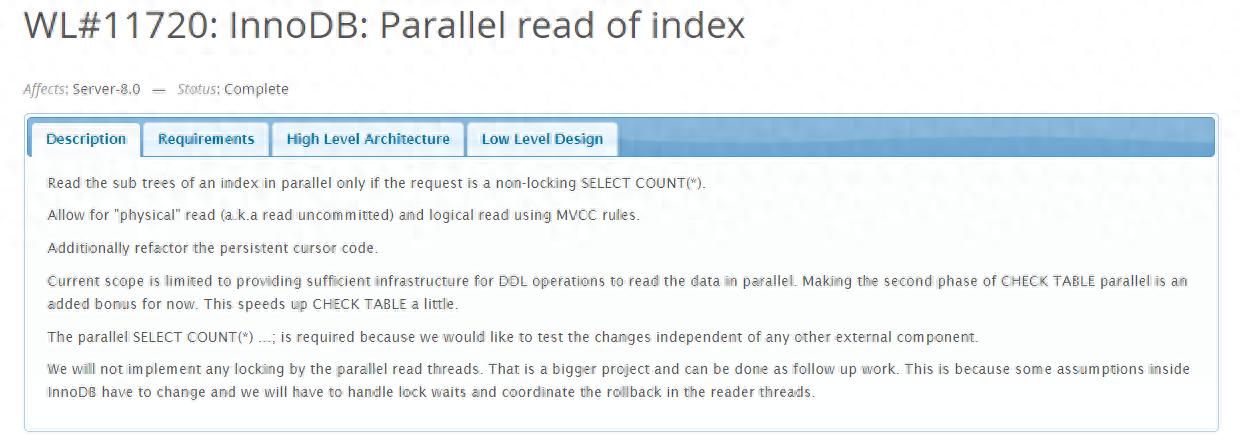
图1 MySQL 8.0 存储引擎并行扫描主键特性
2.1原理介绍
MySQL中并行计数功能在存储引擎层面的实现结构图参见图2。当优化器决定采用并行计数方案时,会生成并行计数操作单元“ator”,并调用API接口“::”,该层包含函数“
::”中调度线程进行拆分、扫描、计数汇总。

图2 并行扫描调度逻辑
此处依据MySQL 8.0.14的源代码,阐释计数并行功能在SQL处理模块和磁盘存储层中的具体运作方式。
2.1.1 COUNT并行在SQL引擎中的实现
SQL引擎层在优化处理时,会识别SQL语句是否仅包含计数功能,这一判断结果会被存储在名为“JOIN:: ”的变量中,该变量的具体定义方式详见下方的代码示例。
/*
当设置join->select_count时,表格不会被优化掉。
调用记录函数的动作将推迟到执行阶段,统计工作则会在优化器选定索引上实施
索引将在find_shortest_key()函数中确定,该函数被调用
optimize_aggregated_query().
*/
这个布尔变量代表状态,它指示是否执行计数操作,具体来说,它属于名为JOIN的类,该变量命名为select_count,其初始值设置为非真值。SQL引擎层在制定执行方案时,会检测变量“JOIN::”的状态,当变量状态为真时,会创建并行统计算子“ator”。用户能够借助“ =TREE”或是“ ”指令来审视执行方案,若方案中带有“Count rows”字样,则表明并行统计功能已启用,具体执行方案见下文展示。
mysql执行查询的树状格式说明,统计lineitem表中的记录条数,具体命令如下:
那排座位,坐满了人,每个人都显得很专注,低着头,认真看着桌面上的东西,周围很安静,只有笔尖划过纸张的沙沙声,偶尔有人轻轻咳嗽,声音很小,几乎听不见,但依然能感觉到空气中的紧张气氛,大家都屏住呼吸,等待着接下来的通知,每个人的脸上都写满了期待,又带着一丝不安,这种情绪在安静的教室里显得格外明显,时间仿佛变慢了,每一秒都感觉很长,大家都坐得很端正,身体挺直,仿佛在用这种姿势表达自己的认真,教室的灯光很柔和,照在每个人的脸上,但没有人抬头,大家的目光都集中在自己的试卷上,那排座位,成了此刻最引人注目的地方,每个人都在默默地努力,等待着属于自己的结果,希望自己的付出能够得到回报,那种心情,复杂而又沉重,但大家都咬牙坚持着,不让自己放弃,因为知道,这关系到自己的未来,所以每个人都必须全力以赴,不能有丝毫的松懈,那排座位,见证了他们的汗水,也承载着他们的梦想,等待着最终的审判,希望每个人都能取得好成绩,实现自己的愿望,那排座位,成了他们心中最坚定的信念,支撑着他们度过这段艰难的时光,等待着属于他们的辉煌时刻。
统计行项目记录的数量2.1.2 COUNT并行在 存储引擎中的实现
SQL引擎调用名为“::”的接口,将优化器选定的索引信息发送给存储引擎,然后接收计数数据。
(2) 存储引擎只支持主键的并行扫描,函数“
::”忽略索引信息,强制选择主键进行并行扫描。
(3) 存储引擎在函数“
对主键索引先进行初步分割,然后安排工作线程对分割后的部分再做细致拆解、遍历、统计。
我们称作响应“::”接口并执行任务的那些执行单元为线程单元,这些单元的调用堆栈详情如下:
不合格计数迭代器读取
get_exact_record_count
handler::ha_records
把索引中的记录提取出来,来自ha_innobase这个数据源
ha_innobase::records
row_scan_index_for_mysql
执行并行查询操作,针对MySQL数据库,统计所有记录数量,结果以星号显示
Parallel_reader::run
Parallel_reader同时执行多个读取操作我们称那个专门响应“::”接口,并且负责执行扫描和计数任务的线程为该线程,这个线程的并发程度,可以通过一个参数来调整
”控制,线程调用堆栈信息如下:
Parallel_reader::worker
Parallel_reader类中的Ctx成员执行遍历操作
Parallel_reader的Ctx结构体执行遍历记录的操作2.2性能提升效果
我们选用4U16G配置的ECS服务器,安装MySQL 8.0.14系统,分配8GB存储空间。借助TPC-H基准测试,将Scale参数调至20,表的主键部分约占17.4GB,二级索引部分占2.3GB,三级索引部分占3.3GB,其数据表构造如下所示。
mysql查询表lineitem的创建信息
*************************** 1. row ***************************
Table: lineitemCreate Table:
CREATE TABLE `lineitem` (
`L_ORDERKEY` bigint NOT NULL,
`L_PARTKEY` int NOT NULL,
`L_SUPPKEY` int NOT NULL,
`L_LINENUMBER` int NOT NULL,
`L_QUANTITY` 为十进制数, 保留两位小数, 不能为空
`L_EXTENDEDPRICE` 为十五位十进制数,包含两位小数,不允许为空
`L_DISCOUNT` 为数值类型,不能为空,精确到小数点后两位,总长度不超过十五位,数值部分允许存在小数,整数部分最大为十四位数字,小数部分最大为两位数字,数值范围受限,不能超过最大允许值,数值精度固定,不允许随意增减小数位数,数值显示时按照指定格式,确保数据一致性,数值输入时进行有效性校验,防止非法数据录入系统,数值存储时占用固定空间,符合数据库设计规范,数值使用时保持一致性,避免数据混乱,数值计算时遵循标准规则,保证结果准确无误
`L_TAX` 为十五位小数类型,包含两位小数,不允许为空,
返回标志位 L_RETURNFLAG 字符类型长度为1不可为空
状态标识字符型单字符非空
`L_SHIPDATE` date NOT NULL,
`L_COMMITDATE` date NOT NULL,
`L_RECEIPTDATE` 日期不允许为空,必须填写具体日期
固定为二十五字符长度的L_SHIPINSTRUCT文本字段,不允许为空
`L_SHIPMODE` 字符类型长度为十位不允许为空
`L注释` 字符串类型,长度为44个字符,该字段不允许为空
主键由`L_ORDERKEY`和`L_LINENUMBER`共同构成,两者组合作为唯一标识,用于区分记录
主键为i_l_orderkey, 其中包含L_ORDERKEY字段
主键名为i_l_partkey_suppkey, 包含字段L_PARTKEY和L_SUPPKEY, 这两个字段共同作为联合主键, 用于关联表中的数据
数据库引擎采用InnoDB, 默认字符集为utf8mb4, 排序规则是utf8mb4_0900_ai_ci表的主键容量高达17GB,无法一次性载入内存池,每次进行计数操作都会引发相近的磁盘I/O活动,大约涉及82万次读写。当前情况下,要改善性能,可以考虑增加并行扫描任务的执行数量
),计数功能表现会逐步增强,单线程操作耗时约八百八十单位,双线程操作耗时约三百单位,四线程操作耗时约一百四十五单位,具体数据请参照图三。

图3 MySQL 8.0 COUNT并行提升效果
2.3约束限制
社区版MySQL的计数并行功能依托于存储引擎完成,仅限于对主键进行并行检索,并未顾及优化器挑选的最适宜索引。若某个表的主键数据量庞大、二级索引数据量相对较少,与老版本(MySQL 5.7)对二级索引执行串行检索相比,当前社区版的并行处理方式无法带来任何性能提升。
社区MySQL的计数并行功能仅适用于不含筛选条件的计数操作,这是由于存储层无法执行过滤性计算所致。
当扫描主键数据体量巨大时,有可能将池内热数据清空,从而造成后续运作出现效率起伏。
社区MySQL的计数并行模式被强制启用,并且无法禁用,一旦碰到前面提到的性能难题,就没办法退回到按二级索引顺序检索数据的方式。
在相同的测试环境与测试模型下,运用“统计全部记录数”的SQL指令,比较MySQL 5.7.44版本和MySQL 8.0.14版本完成操作所需时长,相关数据展示于表1。
表1 MySQL 5.7.44和8.0.14版本中COUNT命令运行时间的比较

当前情况下,MySQL 8.0版本采用四路并行方式检查主键,不过因为处理的数据规模非常可观,从而引发了频繁的磁盘读写操作,最终使得其运行效率不如MySQL 5.7通过顺序方式检查二级索引的表现。
3. (for MySQL) COUNT 优化
MySQL的计数并行处理存在不足,为此专门进行了改进,运用了自主研发的并行查询技术以及计算下放功能,达成了三级并行,提升了计数操作的运行速度,相关架构示意图见第4图。

图4 (for MySQL) COUNT并行优化
3.1原理介绍
下面介绍下(for MySQL) COUNT优化细节。
3.1.1 支持动态关闭社区MySQL COUNT并行
当遇到2.3节的性能问题时,可以通过调整参数“
调整MySQL的计数并行模式,可以使其处于非活动或活动状态,具体操作方法如下:
设置innodb_parallel_select_count为关闭状态,解释以树形格式展示查询语句,查询lineitem表中的记录总数
这一行内容非常长,几乎占据了整个页面,让人感觉有些压抑。
说明:整体统计数量为零
索引扫描行记录,根据i_l_orderkey,成本为12902405.32,预计返回118641035条数据3.1.2 (for MySQL)并行查询特性
针对MySQL版本,实现了并行查询功能,旨在缩短分析类查询的执行周期,以满足企业级应用对查询响应速度的严苛标准,该功能克服了开源MySQL并行查询存在的诸多不便,自主研发的并行查询能够运用主键及二级索引的多种检索路径,可适配绝大多数指令类型。
在执行计数任务时,能够借助PQ的优势,同时检查次级索引,从而增强检索效率。
用户借助提示可以启动PQ,执行方案里一旦出现特定指令,即表明PQ功能已启用。具体操作步骤如下:
mysql解释树格式查询统计行数,从lineitem表获取数据,使用PQ优化器提示
那排座位的第一行,坐满了人,个个都显得很专注,神情严肃,似乎在认真听讲,又好像在思考着什么问题,屋子里安静得能听见呼吸声,只有偶尔响起的翻书声,提醒着这里正在进行着一场重要的学习活动,每个人都被书本吸引住了注意力,沉浸在自己的世界里,周围的一切仿佛都静止了,只有知识和思考在空气中流动,形成了一种独特的氛围,让人不由自主地也投入其中,感受着学习的魅力,那专注的样子,仿佛在告诉别人,这里是一个充满智慧和成长的地方,每个人都值得被尊重,他们的努力和坚持,都在默默地书写着属于自己的未来,这种场景,让人感到无比的敬佩和感动,仿佛看到了希望的曙光,在每个人的眼中闪烁,那是对知识的渴望,对未来的憧憬,也是对生活的热爱,让人不由自主地想要加入他们,一起探索未知的领域,一起追求更高的目标,一起创造属于自己的精彩人生,那排座位,那第一行,成为了这个空间里最亮丽的风景线,让人久久难忘,仿佛在诉说着一个关于坚持和梦想的故事,一个关于奋斗和成长的故事,一个关于希望和未来的故事,这个故事,简单而又深刻,平凡而又伟大,它激励着每一个人,去追求自己的梦想,去实现自己的价值,去创造属于自己的辉煌,那排座位,那第一行,成为了这个空间里最亮丽的风景线,让人久久难忘,仿佛在诉说着一个关于坚持和梦想的故事,一个关于奋斗和成长的故事,一个关于希望和未来的故事,这个故事,简单而又深刻,平凡而又伟大,它激励着每一个人,去追求自己的梦想,去实现自己的价值,去创造属于自己的辉煌。
说明:-> 总计:统计(``.`0`)
收集四个劳动力,同时对线形进行并行检索
-> Aggregate: count(``.`0`)
顺序索引检索行项目表依据i_l_orderkey 代价为4004327.70 预期返回条目数为29660259 3.1.3 (for MySQL)计算下推特性
近场计算是针对 MySQL 数据复杂检索而设计的一种优化技术。对于数据密集型查询,将列选择、汇总计算、条件筛选等任务从处理单元向下分发至分布式存储系统的多个单元,同步进行。这种分发计算方式增强了并行作业水平,降低了数据传输负担和计算单元的负荷,从而提升了查询完成的速率。
对于计数功能,能够借助NDP能力,把汇总过程放到分散式数据仓库里执行,这样能够降低数据传输量,还能增强检索速度。
用户借助提示可以启动NDP,当执行方案里出现NDP这一标识时,表明该功能已经启用。具体操作步骤如下:
mysql解释树展示查询分析过程,选择统计行数,数据来源为lineitem表,包含优化建议,启用PQ查询优化,采用NDP下推策略
*************************** 1. row ***************************
说明:总计:统计`.`0`)
收集四个劳动力,同时在线路项上进行遍历
-> Aggregate: count(``.`0`)
顺序索引检索 lineitem 通过 i_l_orderkey 推送聚合数据 代价为4046562.45 行数为29047384 3.2性能优化效果
采用与2.2节相同的测试场景和测试方案,运行“统计数量”的数据库指令,比较针对MySQL系统,启用快速查询功能与同时启用快速查询及新数据路径功能的响应时长,请参考表格2。
表2 (for MySQL) COUNT操作执行时间

根据检测数据:若仅启用PQ功能,并行查询的并发量定为4,硬盘读写操作大概达到13万次,整个查询过程大约耗费了31秒时间。
同时启用PQ和NDP功能,并行查询的并发量调整为4个,NDP借助IO组合和计算下放,显著降低了磁盘读写,查询时间缩短到1.7秒,与社区版MySQL 8.0.22相比,执行时间长达145秒,COUNT操作的效率提高了八十倍以上。

图5 (for MySQL) COUNT优化提升效果
4.总结
社区版 MySQL 8.0 新增了并行扫描主键的功能,不过它无法并行扫描二级索引,因此当处理大表或者冷数据时(表数据未缓存在内存中),会造成效率下降,企业版 MySQL 利用并行查询和计算下放的功能,成功应对了大表 COUNT 操作缓慢的情况,在常见使用场景下,其性能比社区版并行方案高出八倍以上,让用户享受到更出色的使用感受。
5.相关参考
并行查询(PQ)
算子下推(NDP)
留意#华为云开发者联盟#,请继续向下操作,能够迅速获取华为云最新技术资讯。
华为云资讯_海量数据资讯_人工智能资讯_云端技术资讯_技术创客基地-华为云
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 